
This guide covers Triple Whale's Sync to Data Warehouse feature, which lets you automate data transfers into BigQuery, Snowflake, AWS S3, or Google Cloud Storage at custom intervals. By following these steps, you’ll be able to:
- Connect Your Data Warehouse: Make sure your warehouse is properly set up and that Triple Whale has the correct permissions to write data.
- Schedule the Sync Using Agents: Create an Agent, choosing your connected warehouse as the destination for your data output. Automate how often your data is transferred (daily, hourly, etc.) to keep information up-to-date.
- Test & Deduplicate: Confirm the sync is working correctly, then implement any needed strategies to avoid duplicate rows.
Use these best practices and troubleshooting tips to maintain secure, high-performance data operations.
Compare with Custom SQL APIUse the Custom SQL API instead if you want to run custom queries or fetch data on demand for dashboards, analysis, or pipelines.
Custom SQL API Data Warehouse Sync You pull data via API Triple Whale pushes data to your warehouse You handle scheduling and automation (e.g. dbt, scripts) Built-in scheduling via Agents Slower for large exports; limited by rate and response size No limits on data size—export complete datasets Best for dashboards, ad hoc queries, custom pipelines Best for scheduled exports, BI pipelines, full backfills
Supported Warehouses
- BigQuery: Learn how to set up BigQuery
- Snowflake: Learn how to set up Snowflake
- AWS S3: Learn how to set up AWS S3
- Google Cloud Storage: Learn how to set up GCS
Key Concepts
- Data Structure: Transfer data as tables based on user-defined SQL queries.
- Scheduled Syncs: Schedule syncs using custom intervals within Triple Whale Agents.
- Security and Permissions: Control data access and permissions for secure transfers.
Architecture
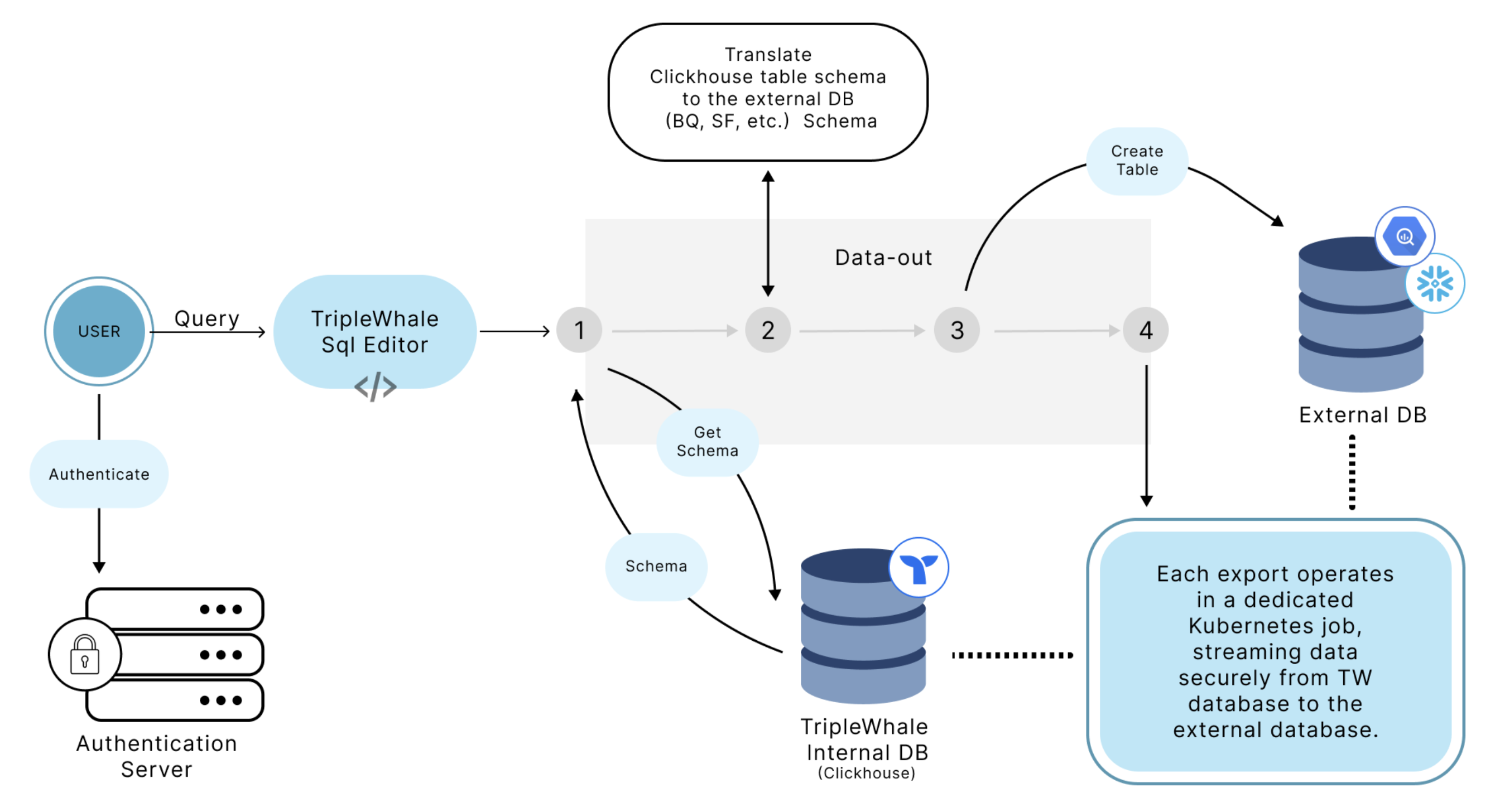
Data Warehouse Sync Architecture Diagram
Security Considerations
- Password Handling: For Snowflake, passwords are used directly without specialized security tokens, so you should create dedicated accounts with limited access to use for syncing data. (For BigQuery, users only need to grant write access to a specific dataset, so password security isn't a concern.)
- Data Protection: Users should create isolated datasets or tables specifically for sync operations to avoid compromising broader data access.
Data Structure and Sync Behavior
Table Creation and Schema
- Automatic Table Creation: Tables are created automatically based on the schema defined in the SQL query executed within the Triple Whale platform.
- Data Types: To ensure compatibility and future-proofing, data types are standardized. For instance, Triple Whale low-cardinality columns are represented as strings for flexibility.
- Schema Adjustments: The output table schema is not editable. If a schema change is needed, a new table must be created.
Data Freshness and Historical Data
- Custom Scheduling: Users can customize how often syncs occur through Triple Whale workflows (e.g., hourly, daily).
- Appending Data: Each sync adds new data rows; existing data is not replaced. Users should manage deduplication on their end if needed.
- Historical Sync: Users can run custom SQL queries to extract historical data in batches (e.g., month-by-month) for backfilling.
Common Errors and Troubleshooting
- Connection Issues: If the setup fails, verify that the provided credentials, project ID, and dataset ID are correct. Restart the process if errors persist.
- Permission Errors: Ensure that the service account or user account has been granted the necessary permissions for writing data.
- Table Name Conflicts: Verify that the new table name is unique to prevent overwrite or duplication errors.
Best Practices
- Managing Schema Changes: If a schema change is necessary, create a new table with the updated schema.
- Performance Optimization: For optimal performance, avoid syncing overly large data sets at frequent intervals. Break down data into manageable chunks if possible.
- Testing Connections: Run a test sync with a small query to confirm that the connection works before syncing larger datasets.
- Permission Management: To maintain data security, manually restrict data access through allow-listing or by creating service accounts with user-specific permissions.
- Data Segmentation: Sync data in manageable batches to optimize performance and avoid timeouts.
FAQs
How do I activate my data warehouse sync?
You can automate exports using Agents, where you define the data source (e.g., SQL query), destination (BigQuery, Snowflake, etc.) and choose a sync interval (daily, hourly, etc.). Once saved, the Agent continuously appends data to your warehouse based on your schedule.
How often does the sync run?
Users can configure the sync frequency within the Triple Whale Agent Scheduler.
Is data deduplication handled?
No, users need to implement deduplication strategies within their data warehouse.
What if schema changes are required?
Create a new table and update your workflow to use the new schema.
How secure is the data during the sync process?
Data security is maintained through user-defined permissions and encrypted connections. Users should manage data access through restricted accounts or specific data sets.
What happens if a sync fails?
While detailed client-facing error logs are not yet available, users should check connection settings and workflow configurations. If problems persist, contact Triple Whale support.
Can I include specific fields or exclude certain data?
You can customize the SQL query to control the specific data structure and content that is synced.