
This document provides advanced setup guidance, troubleshooting tips, and key technical considerations for Triple Whale's Sync to Warehouse (Data Out) feature, supporting both BigQuery and Snowflake. Learn more about Leveraging Data-Out Capabilities in Workflows.
Overview
Triple Whale's Sync to Warehouse feature lets users automate the transfer of data from Triple Whale into their own data warehouses at custom intervals, using workflows.
Key Concepts
- Supported Warehouses: BigQuery and Snowflake
- Data Structure: Data is transferred as tables based on the structure defined by user queries.
- Scheduled Syncs: Syncs occur at intervals defined within Triple Whale workflows.
- Security and Permissions: Users control data access and permission settings for secure transfers.
Architecture
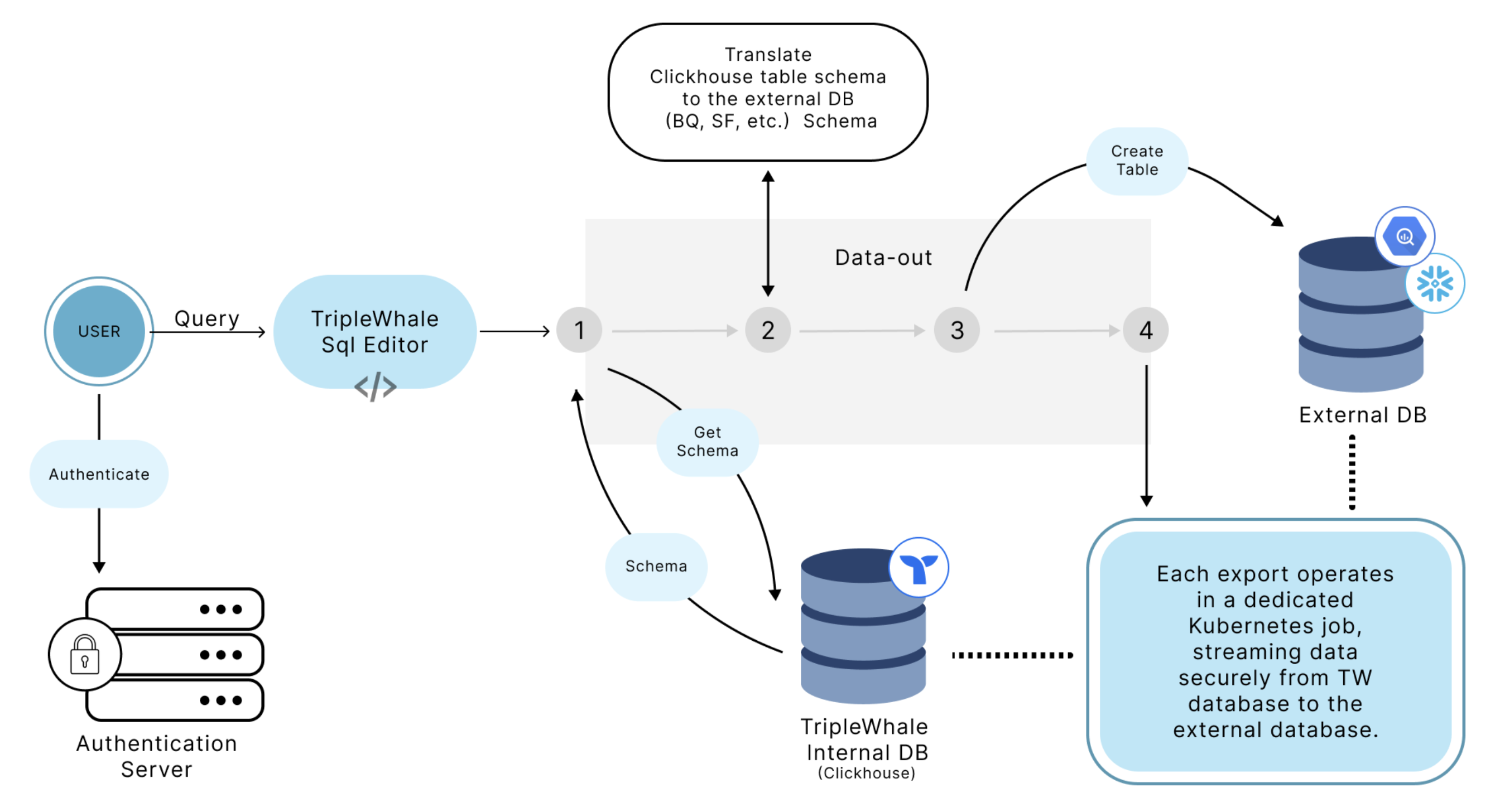
Setup and Configuration
BigQuery
-
For step-by-step setup guidance, see the BigQuery Integration guide.
-
Project ID and Dataset ID: Users must provide a project ID and dataset ID where data will be written.
-
Service Account Permissions: Triple Whale requires you to grant BigQuery editor permission to the
[email protected]service account on the specific dataset you are syncing, in order to create and write to tables in that dataset.-
To grant BigQuery editor permission to the service account, navigate to Share > Manage Permissions
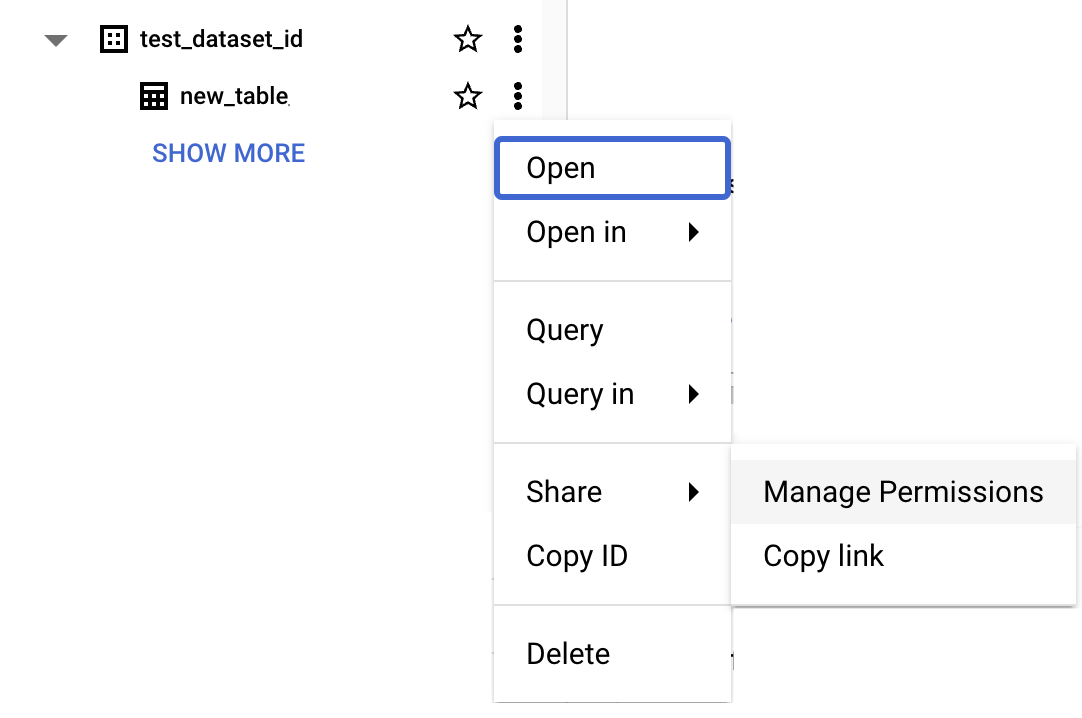
-
Click Add Principal

-
Add
[email protected]as New principal, with the role of BigQuery Data Editor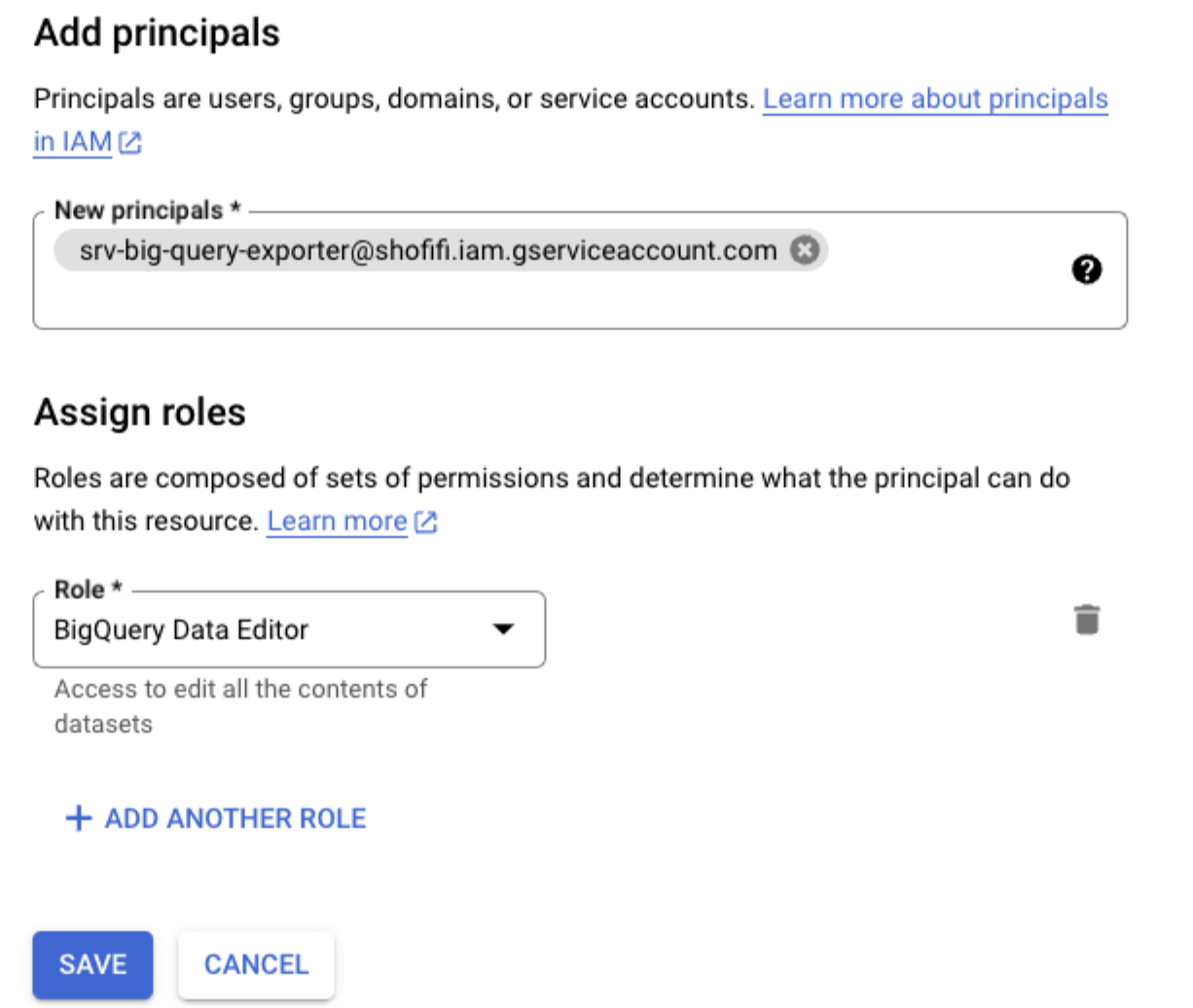
-
Snowflake
-
For step-by-step setup guidance, see the Snowflake Integration guide.
-
Database Credentials: Users must provide the Account ID, Warehouse, Database, Schema, Username, and Password
-
To find the Account ID in Snowflake, click Copy account URL and select the ID portion of the URL (example ID:
PF05357.us-central1)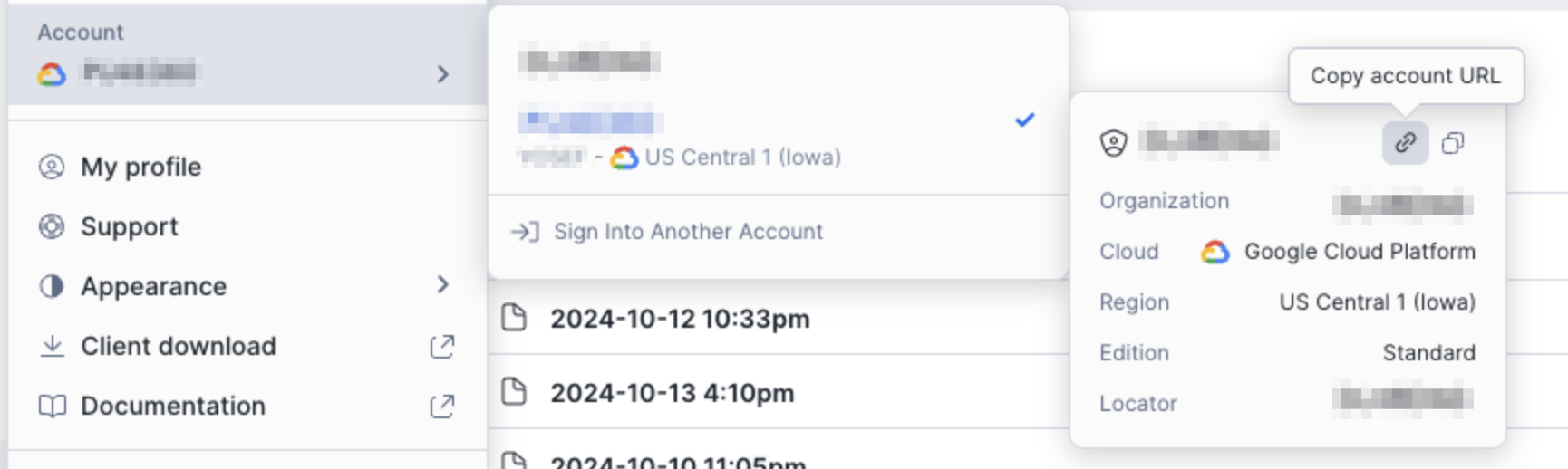
-
-
Permissions: Ensure that the user account has sufficient privileges to create tables and insert data.
Security Considerations
- Password Handling: For Snowflake, passwords are used directly without specialized security tokens. Users are advised to create dedicated accounts with limited access for syncing purposes. (For BigQuery, users only need to grant write access to a specific dataset, so password security isn't a concern.)
- Data Protection: Users should create isolated datasets or tables specifically for sync operations to avoid compromising broader data access.
Data Structure and Sync Behavior
Table Creation and Schema
- Automatic Table Creation: Tables are created automatically based on the schema defined in the SQL query executed within the Triple Whale platform.
- Data Types: To ensure compatibility and future-proofing, data types are standardized. For instance, Triple Whale low-cardinality columns are represented as strings for flexibility.
- Schema Adjustments: The output table schema is not editable. If a schema change is needed, a new table must be created.
Data Freshness and Historical Data
- Custom Scheduling: Users can customize how often syncs occur through Triple Whale workflows (e.g., hourly, daily).
- Appending Data: Each sync adds new data rows; existing data is not replaced. Users should manage deduplication on their end if needed.
- Historical Sync: Users can run custom SQL queries to extract historical data in batches (e.g., month-by-month) for backfilling.
Common Errors and Troubleshooting
- Connection Issues: If the setup fails, verify that the provided credentials, project ID, and dataset ID are correct. Restart the process if errors persist.
- Permission Errors: Ensure that the service account or user account has been granted the necessary permissions for writing data.
- Table Name Conflicts: Verify that the new table name is unique to prevent overwrite or duplication errors.
Advanced Tips
Schema Management
- Managing Schema Changes: If a schema change is necessary, create a new table with the updated schema.
- Performance Optimization: For optimal performance, avoid syncing overly large data sets at frequent intervals. Break down data into manageable chunks if possible.
Best Practices
- Testing Connections: Run a test sync with a small query to confirm that the connection works before syncing larger datasets.
- Permission Management: To maintain data security, manually restrict data access through allow-listing or by creating service accounts with user-specific permissions.
- Data Segmentation: Sync data in manageable batches to optimize performance and avoid timeouts.
FAQs
How often does the sync run?
Users can configure the sync frequency within the Triple Whale Workflow Scheduler.
Is data deduplication handled?
No, users need to implement deduplication strategies within their data warehouse.
What if schema changes are required?
Create a new table and update your workflow to use the new schema.
How secure is the data during the sync process?
Data security is maintained through user-defined permissions and encrypted connections. Users should manage data access through restricted accounts or specific data sets.
What happens if a sync fails?
While detailed client-facing error logs are not yet available, users should check connection settings and workflow configurations. If problems persist, contact Triple Whale support.
Can I include specific fields or exclude certain data?
You can customize the SQL query to control the specific data structure and content that is synced.